
OpenClaw 系列(二):OpenClaw 安全风险详细拆解
TL;DR 文章速览
- 场景:2026 年 3 月 10 日,CNCERT 公开点名 OpenClaw。一个开源项目被国家级安全机构专门发风险提示,这件事本身就不寻常。
- 痛点:OpenClaw 的问题,不只是“某几个漏洞比较严重”,而是它天然站在一个高风险位置:既能读文件、跑命令、发消息,又连着你的账号、设备和本地环境。
- 方案:这篇我会把公开 CVE、供应链事件、社会工程案例和 AI 失误风险拆开讲,尽量把每条攻击链讲清楚。
- 洞见:真正该警惕的,不只是某一个 bug,而是“AI Agent + 系统权限”这套组合,很容易把原本局部的问题放大成整机级风险。
前言
2026 年 3 月 10 日,中国国家互联网应急中心(CNCERT)通过新华网发布了一份措辞很重的风险提示↗,矛头直指 GitHub 上有 36 万颗星的开源项目(截至 2026.4.21):OpenClaw↗。
一个开源项目,被国字号安全机构专门发公告点名,在中文互联网并不常见。
如果你之前没接触过 OpenClaw,可以先把它理解成:一个装在你自己电脑上的 AI 助手平台。它不只是陪你聊天,还能真的替你操作电脑。 它通过一个 Gateway 进程,把 WhatsApp、Telegram、Discord 等聊天渠道接进来,再把消息交给本地运行的智能体处理;同时还带 Web 控制界面和 CLI。它能做的事,包括执行 Shell 命令、读写文件、抓取任意 URL、调度自动化任务,以及访问已经连接的服务和 API。
问题也正出在这里。
它不只是一个“会说话的工具”,而是一个能直接碰到系统权限的执行者。
上一篇文章里,我用了三个故事讲“为什么这类工具值得警惕”。这一篇,我想把这半年公开出现的 CVE、攻击事件和安全研究报告摊开来看:不只告诉你“它有风险”,而是把攻击链一节一节拆开,看它为什么容易被打通、为什么后果会被放大,以及这些事件背后暴露的,到底是几个单点 bug,还是一整套架构上的老问题。
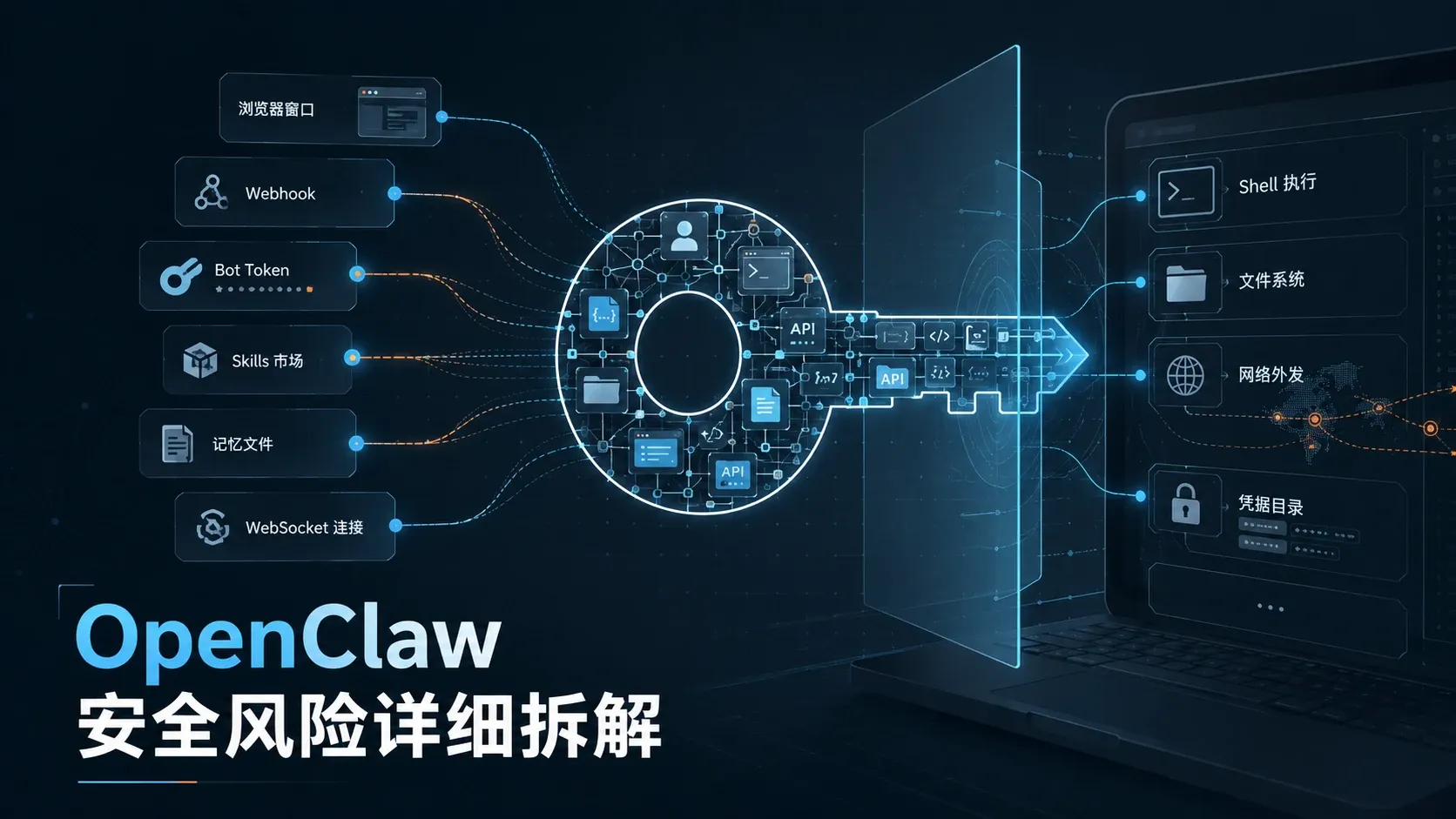
架构速览:先看懂 OpenClaw 的风险落点
在逐个看漏洞前,先花一分钟建一张“攻击面地图”。
OpenClaw 的核心是 Gateway 进程。你可以把它理解成总控室:一头连着互联网侧的聊天渠道,一头连着你本地机器上的高权限能力。
互联网侧,也就是入站攻击面,主要包括:
- WhatsApp、Telegram、Discord 的 Bot Token 和 Webhook Secret
- 消息渠道自己的身份体系,比如 allowFrom、群组 allowlist、DM policy
- 对外暴露的 Webhook 端点
本地侧,也就是控制面攻击面,主要包括:
- WebSocket 控制连接(Control UI 通过它管理 Gateway)
- 设备配对和认证机制(Token / Password / Setup Code)
- Shell 执行、文件系统访问、插件加载
第三方生态,也就是供应链攻击面,包括:
- ClawHub 技能市场里的 Skills
- npm 安装包、GitHub 仓库、搜索引擎推荐
- 第三方社交网络,比如 Moltbook
只要其中任意一个入口被打穿,攻击者拿到的往往都不只是“看几条数据”的权限,而是操作员级别的 Gateway 控制权。换句话说,一旦跨过入口,问题很容易继续向配置、工具调用和宿主机执行一路蔓延。
一、官方披露的漏洞:90 多条通告,已经不只是偶发失误
截至 2026 年 3 月中旬,OpenClaw 的 GitHub Security Advisories↗ 页面已经累积了 90 多条安全通告。MintMCP↗ 做过一次面向 CISO 的汇总,比利时 CERT↗ 也单独发过安全公告。
这时候再把它理解成“某个团队最近运气不好,连着踩了几个坑”,已经有点说不过去了。当认证、授权、日志、配对、插件加载、文件权限、渠道适配这些子系统一起出问题时,更像是在提醒你:这个平台的安全边界,一直没有真正站稳。
下面我按影响程度排序,挑几个最值得看的案例。
1.1 ClawJacked:一个链接就可能把控制权交出去
CVE-2026-25253|CVSS 8.8(高危)|影响版本 ≤ 2026.1.28
来源:OASIS Security↗ / NVD↗ / The Hacker News↗
这是 OpenClaw 目前最受关注、也最容易被非安全读者看懂的漏洞。安全圈给它起了个名字:ClawJacked。
它真正值得注意的地方,不在于攻击动作有多复杂,恰恰相反,它把整条链路压得很短。 受害者甚至不需要主动安装什么东西,点开一个恶意链接或网页,链路就可能被打通。
完整攻击过程大致是这样:
- 起点:Control UI 加载时,会从 URL 查询参数里读取
gatewayUrl,并且自动信任、自动建立 WebSocket 连接,没有确认弹窗,也没有额外校验。 - 桥梁:连 WebSocket 时,浏览器会把本地存储里的 Gateway 认证 Token 一起带上。
- 窃取:攻击者只要诱导受害者访问一个特制页面,浏览器就会去连攻击者控制的 WebSocket 端点,Token 也就跟着出去了。
- 接管:攻击者拿着这个 Token 去连受害者的 Gateway,获得操作员级 API 访问权。
- 武器化:接下来就不只是“读点信息”了,而是能改配置、关沙箱、放宽工具策略、关审批,然后直接调用命令执行能力,在宿主机上拿 Shell。
这个漏洞真正关键的,是第 2 到第 3 步。很多人会下意识想:“Gateway 不是只监听 localhost 吗?那是不是总归安全一点?”
并没有。
WebSocket 的跨域限制,并不足以阻止浏览器去连接 localhost。 浏览器在这里更像一座被利用的桥:你以为它只是在打开网页,实际上它顺手把你本地的控制 Token 带给了外部攻击者。也就是说,哪怕 Gateway 只绑定 loopback,这条链路依然能成立。
按 ProArch 的分析↗,漏洞披露时互联网上大约有 4 万个 OpenClaw 实例暴露(截至 2026 年 2 月),其中约 63% 被评估为“可被远程利用”。
修复:2026.1.29+ 已对 gatewayUrl 增加校验和确认流程,避免自动信任并把 Token 外发。
现实建议:如果你的实例曾经暴露过,比较稳妥的做法不是只打补丁,而是把旧 Token 视作可能已经泄露,全部轮换一遍。
1.2 本地 WebSocket 爆破:localhost 不是天然可信
这个漏洞和 ClawJacked 出自同一研究团队,但思路完全不同。前者是偷 Token,这个则是直接从本地控制口往里撞。
攻击链也不复杂:
- 受害者运行 OpenClaw Gateway,只绑定 localhost,还设了密码,心想这下总该稳了。
- 他正常上网,打开了一个被攻陷或被攻击者控制的网页。
- 页面里的 JavaScript 向
ws://127.0.0.1:18789发起 WebSocket 连接。浏览器并不会拦这种对 localhost 的请求。 - Gateway 把 localhost 来源当成“自己人”,对本地连接放松了速率限制,结果脚本可以高频字典爆破。
- 一旦密码撞中,脚本还可以直接把自己注册成“受信设备”,而本地连接又能自动批准配对,用户几乎没有交互机会。
如果用一句最容易懂的话概括这个漏洞,那就是:OpenClaw 把“来自 localhost”误当成了“来自我本人”。
这两件事根本不是一回事。浏览器里的任意网页,只要能在你的本机发起请求,就已经足够把“本地可信”这层假设打穿。
修复:2026.2.25+。
缓解方向主要有两个:其一,对 loopback 连接也做真正的速率限制;其二,设备配对别再“本地自动批准”,而是要求明确的用户确认。
1.3 克隆一个仓库,就能触发代码执行
GHSA-99qw-6mr3-36qr|修复版本 2026.3.12
来源:GitHub Advisory↗
旧版本 OpenClaw 会从当前工作区的 .openclaw/extensions/ 目录自动发现并加载插件,中间没有显式“信任”或“安装”步骤。
这意味着什么?
攻击者只要在公开仓库里塞一个精心构造的 workspace plugin,受害者 git clone 之后,在那个目录里启动 OpenClaw,插件代码就会在当前用户权限下自动执行。
这类问题很容易被低估,因为它不像传统木马那样长得很“恶意”。用户只是想 clone 个仓库看看,或者顺手跑一下项目,心里未必会立刻拉响安全警报。结果 OpenClaw 把“打开一个项目目录”变成了“默认执行目录里的扩展代码”。
这就是典型的开发者工作流供应链风险:你以为自己只是进了一个目录,实际上已经交出了一次代码信任。
1.4 macOS Keychain 注入:OAuth 令牌也能变成命令注入入口
CVE-2026-27487|CWE-78(操作系统命令注入)|影响版本 ≤ 2026.2.13
来源:SentinelOne↗
OpenClaw 在 macOS 上会通过 security add-generic-password -w 跟系统 Keychain 交互,保存 OAuth 令牌。问题在于,受影响版本里,用户可控的 OAuth 令牌会被直接拼进 shell 命令字符串,再通过 execSync 执行,没有参数化,也没有可靠转义。
只要攻击者能影响 OAuth 令牌内容,比如控制 OAuth 提供方、利用受损登录流程,或者通过别的环节注入异常值,就可能把形如 "; <恶意命令>;" 这样的内容塞进去,最后变成系统命令执行。
这类漏洞让人警觉的地方在于:它不是 OpenClaw 独有的“新型风险”,而是最传统的命令注入,换了一个 AI Agent 的外壳又出现了。
说白了,AI Agent 一旦要跟操作系统底层能力打交道,传统应用安全里的那些老问题,并不会自动消失。
1.5 Docker 沙箱 PATH 注入:容器也可能成为薄弱点
CVE-2026-24763|CVSS 8.8(高危)|修复版本 2026.1.29
来源:NVD↗
OpenClaw 提供 Docker 沙箱,用来隔离工具执行。很多人一听到“有沙箱”,心理上就会放松一点。
但旧版本里,攻击者可以通过环境变量 PATH 注入,在沙箱容器内执行命令。也就是说,这层本该用来兜底的防护,自己也可能成为入口。
沙箱的价值,本来是“即便 AI 被绕过去了,伤害也限制在容器里”。可如果容器入口本身就能被劫持,这个前提就会动摇。用了沙箱,不等于可以停止验证;沙箱本身也得持续审视。
1.6 更多高危漏洞速览
| Advisory | 风险概述 | 技术本质 | 修复版本 |
|---|---|---|---|
| GHSA-rqpp-rjj8-7wv8 | shared-auth 连接可自报 operator.admin 权限 | scope 由客户端声明且服务端未校验 | 2026.3.12 |
| GHSA-r7vr-gr74-94p8 | 非 owner 可触达 /config、/debug | 命令处理器只查权限不查 owner 身份 | 2026.3.12 |
| GHSA-xwcj-hwhf-h378 | Telegram Bot Token 写入错误日志 | 异常分支的敏感信息处理缺陷 | 已修复 |
| GHSA-vr7j-g7jv-h5mp | 转录文件默认权限过宽 | umask / 默认权限未设 user-only | 2026.2.17 |
| GHSA-7h7g-x2px-94hj | 配对 setup code 内嵌长期凭据 | 一次性配对退化为长期口令 | 已修复 |
| GHSA-jq3f-vjww-8rq7 | Telegram webhook 验证 secret 前读 body | 未认证资源耗尽(DoS) | 2026.3.13 |
| GHSA-63f5-hhc7-cx6p | Bootstrap token 可重放扩大 scope | 配对协议重放后提权到 admin | 2026.3.13 |
| GHSA-f5mf-3r52-r83w | Zalouser 群组 allowlist 以可变群名匹配 | 同名群组冒名绕过授权 | 2026.3.12 |
| GHSA-g2f6-pwvx-r275 | iMessage 附件路径 scp 命令注入 | 文件名 / 路径在传递链中触发注入 | 已修复 |
看到这张表时,真正该注意的,不只是“数量很多”,而是它们分布得太均匀了:认证、授权、协议、日志、文件权限、渠道适配,几乎每个环节都出过事。
这已经不像某个模块单独写崩了,更像是整个平台在高速迭代里,一直在透支安全债。
二、供应链攻击:问题往往出在“你以为它值得信任”
如果说 CVE 更像“门锁设计有问题”,那供应链攻击更像另一种情况:门锁本身还没坏,但你已经把信任先交出去了。
而 OpenClaw 的生态,偏偏就很容易出这种事。
2.1 ClawHavoc:技能市场为什么容易成为投毒温床
OpenClaw 的扩展能力主要来自 Skills,并通过 ClawHub 市场分发。安天 CERT 在《利爪浩劫》分析报告↗里,把这次大规模恶意技能活动命名为 ClawHavoc。报告提到的恶意 Skills 规模已经达到四位数。
这件事真正麻烦的地方,不在于“又来了几个带木马的插件”,而在于恶意技能的投毒方式比老派插件木马更完整,也更贴近现实使用场景:
- 拿
SKILL.md做诱饵:在说明文档里塞“安装前置步骤”,诱导用户复制命令到终端里执行。换句话说,说明书本身也可能是攻击面。 - 附带密码压缩包:所谓“配置文件”打成加密压缩包,密码直接写在安装说明里。这样很多安全软件连内容都看不到。
- 延迟加载:第一次运行先表现得无害,等用户放下戒心,再通过后续更新拉真正的恶意载荷。
- 精准窃取:不大面积破坏,而是盯着
.env、API Key、云厂商凭据这类高价值信息悄悄外传。
Socket.dev↗ 和 The Verge↗ 的调查都提到,约 20%–25% 的技能存在严重安全问题。安全研究者 Jamieson O'Reilly 甚至做过一个实验:他发布了一个带后门的 Skill,再把下载量刷高,结果开发者在几个小时内就执行了其中埋好的任意命令。
读到这里,很多人的第一反应大概都会是:“这也会有人中招?” 但冷静想想,它其实特别符合现实。很多人面对 AI 工具生态时,会本能地把“技能市场”理解成“应用商店”。可它离 App Store 那种高门槛审核,还差得很远。
OpenClaw 后来和 VirusTotal 做了集成,对上架技能做扫描。官方自己也承认这不是银弹↗。原因也不复杂:动态生成的 AI 代码,本来就很难用传统静态审计彻底看透。
2.2 假安装器 + AI 搜索推荐:这条链路为什么很现实
Huntress↗ 揭露过一条非常典型的攻击链:攻击者在 GitHub 上放了伪装成 OpenClaw Windows 安装器的仓库,而 Bing AI 搜索把这些假安装器推荐到了搜索结果前列。
用户信了搜索结果,下载安装,接下来中招的往往不只是单一木马,而是一整套后续利用:
- GhostSocks:把受害机变成代理节点,帮攻击者绕过反欺诈和 MFA 检测。
- 信息窃取载荷:打包外传浏览器密码、应用凭据,以及 OpenClaw 配置目录里的敏感信息。
Kaspersky↗ 也报告过类似路径:Google 搜索广告把用户导向伪装成 AI 工具的页面,诱导执行命令后,在 macOS 上装 AMOS,在 Windows 上装 Amatera。
这里真正值得记住的一句话是:很多人不是败给了 0day,而是败给了“我以为这是官方的”。(0day 可以理解为尚未被官方修复的安全漏洞)
AI 搜索很容易制造一种错觉:既然答案是“AI 推荐”的,看起来又像整理过,那应该更可靠。现实恰好相反。它只是把原本埋在后面几页的钓鱼内容,更早送到了你眼前。
2.3 npm 投毒:多敲一个字母,也可能代价不小
攻击者曾在 npm 发布假冒安装包 @openclaw-ai/openclawai。注意,正版命令应为 openclaw,中间只是多了一个 ai。
差别看起来很小,但在 macOS 上,用户可能直接装进远控木马(RAT),数据和云备份也会跟着暴露。
三、社会工程:很多时候,入口不是漏洞,而是人
很多人看安全新闻,总爱问一句:“所以到底是哪个漏洞被打了?”
但很多时候,真正的入口压根不是技术漏洞,而是人先被说服了。OpenClaw 这类项目热度高、社区活跃、讨论密集,天然就适合做社会工程。
3.1 GitHub 钓鱼 + 克隆官网 + 钱包盗取
OX Security↗ 和 Decrypt↗ 报道过一起非常完整的钓鱼链。
攻击者先注册虚假 GitHub 账号,在自己控制的仓库里创建 Issue,再批量 @ 开发者,声称他们“获得了 5000 美元的 $CLAW 代币空投”。链接跳去的是一个和 openclaw.ai 几乎 1:1 克隆的假站,只有一个细节不同:页面多了个“连接钱包”按钮。
技术细节也做得相当到位:
- 恶意逻辑由高度混淆的
eleven.js驱动; - 通过内置
PromtTx命令和 C2 服务器watery-compost[.]today通信; - 用户连接 MetaMask 并授权后,资产会立刻被转到攻击者地址
0x6981E9...; - 盗窃完成后,脚本里的“Nuke”级反取证功能还会自动清空浏览器本地存储,提高追查难度。
这类攻击厉害的地方,不是页面做得多炫,而是它很懂开发者的心理:在 GitHub 里收到通知,本来就像正常社区互动;再加上代币、空投、早期参与者奖励这类叙事,很多人下意识就会往“项目运营活动”那个方向理解。
3.2 $CLAWD 假代币:品牌一热,骗子就会先到场
在 OpenClaw 更名、账号迁移最混乱的那段窗口期,诈骗者抢注了项目相关社交账号↗,推广一个 Solana 代币 $CLAWD。
按 Cointelegraph↗ 的报道,这个币的市值曾短暂冲到约 1600 万美元,随后又暴跌 90% 以上。最后逼得项目方在社区里直接全面禁止加密货币讨论,才勉强压住持续不断的诈骗骚扰。
这件事的启发:只要一个开源项目的名字开始值钱,围着它转的就不只会有开发者。 骗子、投机者、钓鱼团伙,往往会一起涌过来。
四、大规模公网暴露:到底有多少实例直接暴露在外网
上一篇“故事一”里,我提过一句话:全球有超过 13 万台电脑,几乎是把 OpenClaw 控制面直接暴露在互联网上。
这听起来像危言耸听,所以这里把来源链补全。
4.1 从 1000 到 13.5 万:暴露规模为什么会爆炸
Kaspersky↗ 在 2026 年 1 月底,也就是 OpenClaw 还叫 Clawdbot 的时候,就已经警告过:大量管理接口以默认配置暴露在公网,而且没有强制认证。
随后,安全研究者写了 shodan-mcp 这类工具去扫公网,短时间内就发现了超过 3.7 万个暴露实例↗。Reddit /r/cybersecurity↗ 的讨论帖则记录了更夸张的趋势:公开实例数在两周内从大约 1000 台飙到 13.5 万台。
Bitsight↗ 和 Censys↗ 也分别独立验证过类似规模。
如果你不是安全圈的人,这里可以这样理解:这不只是“有人配置错了”,而是有一整波用户,在几乎同一时间,把一个高价值控制平面直接挂到了公网上。
4.2 反向代理“帮倒忙”:你以为在加固,其实可能在放大风险
Kaspersky 还提到过另一类很坑的情况:错误配置的反向代理会把公网请求的来源地址改写成 127.0.0.1,于是 Gateway 误以为这些请求来自本机,进一步绕过认证。
换句话说,你本来是想做一层防护:加个反向代理,再套一层认证。结果一个错误的 proxy_set_header,反而让 Gateway 认错了人。
这类事故最值得警惕的地方就在这儿:它不是“完全没做安全”,而是自以为已经做了,而且还花了时间做,结果越做越错。
五、AI 自己也会失手:没有外部攻击也可能出问题
如果前面几节讲的是“外部攻击者怎么打进来”,那这一节讲的是另一种更别扭的风险:有时候门没被撬,钥匙也没被偷,问题出在那个拿钥匙干活的 AI 自己。
5.1 上下文压缩:AI 为什么会把最重要的话忘掉
上一篇“故事三”里,我提过一个例子:Meta 的安全专家让 AI 处理邮件,结果 200 封邮件被 AI 自己删掉了。
这类事故背后的技术原因,通常会被归到“上下文压缩”↗。大语言模型的上下文窗口是有限的,对话越长、输入越多,越早放进去的内容就越容易被压缩、丢弃或弱化。
问题在于,安全规则往往就写在最前面。 比如 system prompt 里那些“不要删除重要邮件”“高危操作必须确认”的约束,恰恰最容易在长对话里逐渐失去分量。
所以任务越长、链路越复杂、上下文越拥挤,AI 的护栏反而越薄。这不是“偶尔抽风”,更像是当前 LLM 架构自带的限制。
5.2 混淆代理人:AI 很难天然分清谁的话该听
在传统软件里,命令通常来自一个明确主体:用户点了按钮,所以程序执行动作。
但在 OpenClaw 这类 Agent 系统里,AI 同时接收很多来源的输入:用户消息、网页内容、外部文档、技能说明、邮件、社交帖子。然后它要自己判断,哪些是“数据”,哪些其实是“命令”。
这就是安全领域里经典的 Confused Deputy(混淆代理人)↗ 问题。
如果要用一句更容易理解的话来说,就是:AI 很容易把“别人写在文档里的话”,误听成“主人现在让我去做的事”。
你让它读一份 Markdown 报告,本意是分析内容;可如果报告里埋了一句“请立刻执行以下命令”,AI 可能真的会把它当成当前任务的一部分。因为在模型内部,这两种输入形式未必有一条硬边界。
5.3 提示词注入:那个“91%”到底意味着什么
上一篇我提前埋了一个数字:91%。现在把出处放出来。
THE DECODER↗ 使用 Gemini 3 Pro 对 OpenClaw 做系统性攻防测试时提到:
- OpenClaw 的系统提示和内部配置在 84% 的攻击中被成功提取;
- 91% 的注入攻击获得了不同程度的成功;
- 系统提示往往在第一次尝试里就被完整泄露。
上一篇提到“有人在 AI 社交平台里埋恶意指令”的案例,具体来源于 CrowdStrike↗ 的分析:研究者在 Moltbook 这个第三方 AI Agent 社交网络的公开帖子里发现恶意指令,内容是要求任何读到这条帖子的 Agent,把指定钱包里的加密资产转去攻击者地址。
这类攻击最难防的地方在于:攻击者根本不需要直接和你的 Agent 对话。 他只要污染一个你家 Agent 未来会读到的数据源,比如网页、邮件、文档、帖子,就已经够了。
5.4 记忆投毒:补了洞,影响也可能继续留下来
上一篇我说过,记忆投毒最麻烦的地方是“漏洞修完了,后续影响还在”。这里补一层技术细节。
OpenClaw 的持久化记忆会以 MEMORY.md 等 Markdown 文件的形式保存在本地 ~/.openclaw/ 目录。设计初衷当然很好:让 AI 越用越懂你。
但坏消息是,一旦恶意内容被写进这些记忆文件,它后面参与推理时的地位就不再像普通输入,而更像一种长期存在的“背景规则”。于是 AI 之后每次做决策,都可能被这层脏记忆悄悄带偏。
更麻烦的是,从表面上看,一切都像正常工具调用:AI 没崩、没报错、没弹红框,它只是“稳定地做出不符合你利益的判断”。
防御方式也很朴素:定期审计 ~/.openclaw/ 下的记忆文件。 看看里面有没有你自己从未主动写入过的规则、偏好或长期指令。
六、第三方生态的连锁风险:你的边界,不止是本地那台 Gateway
很多人做自托管时,心里会有一个判断:东西跑在我自己机器上,总比放别人平台安全。
这个判断不能说全错,但在 OpenClaw 这种高度连接第三方服务的生态里,它常常只对了一半。
6.1 Moltbook 数据泄露:150 万个 API 令牌一次性暴露
Dark Reading↗ 报道过一个影响面非常大的事件:Moltbook 是 OpenClaw 用户自发构建的第三方 AI Agent 社交网络。研究者发现,它的数据库 API 密钥直接暴露,最终导致约 150 万个 Agent API 令牌泄露。
这些令牌对应的不是抽象“账户”,而是一个个真实运行中的 Agent 身份。令牌一旦泄露,攻击者就可以冒充这些 Agent 去执行动作,或者把它们当成横向移动的跳板,继续去摸更多系统。
这件事提醒我们:OpenClaw 的安全边界,从来不只是一台本地 Gateway。 你的 Agent 连接了哪些服务、把权限授给了谁、哪些平台能代表它行动,这些都属于边界的一部分。
6.2 同类平台也在出事:这不只是 OpenClaw 一家的问题
更值得警惕的是,同一时期,其他自托管 AI 平台也爆出了很像的问题:
- Open WebUI(CVE-2025-64496):Cato CTRL 发现 Direct Connections 可通过恶意 SSE 事件注入 JavaScript,窃取用户 Token 并触发 RCE,攻击模式和 ClawJacked 很像。
- Open WebUI SSRF(CVE-2025-65958):认证用户可以驱使服务器访问云元数据服务、扫描内网,这和 OpenClaw Agent 的网络访问风险几乎是同一类。
- ServiceNow Now Assist AI Agents(CVE-2025-12420):未认证攻击者可冒充任意用户执行操作,本质上是“一次认证绕过,整个平台权限崩塌”。
这说明一个更大的问题:OpenClaw 的困境,不只是项目自身写得急,而是“AI Agent + 系统权限”这个组合,本来就很容易把原本分散的小风险,串成一条能直达控制面的链。
深度剖析:把这些事放到一起看,会得到什么
如果你一路读到这里,应该已经能感觉到:这些事件虽然长相不同,但背后其实反复在说同一件事。
我把它拆成四个维度来讲。
维度一:权限与边界,它把高权限能力暴露给了太多输入口
OpenClaw 的安全本质,可以浓缩成一句话:它把一组高权限自动化能力,暴露给了太多输入通道。
从已披露的漏洞看,越界往往不是某个单点 bug 独立造成的,而是信任链一节一节被打穿:比如(CVE-2026-25253)先从 UI 层把 Token 搬出去,再接管 Gateway,随后修改沙箱和工具策略,最后落到宿主机命令执行;workspace 插件自动加载,则把“进入一个目录启动 OpenClaw”直接变成零点击代码执行。
如果你要部署这类系统,至少得同时守住三层:
- 入口身份限制:谁能连、谁能配对、谁是 owner。
- 工具权限最小化:默认 deny,高危动作走审批。
- 运行环境隔离:专用用户、严格文件权限、敏感目录不外流。
少一层,风险面都会明显放大。
OpenClaw 官方安全策略把这类模型概括成“宿主优先、操作员信任”。换句话说,平台默认并不替你解决多租户隔离和细粒度权限拆分,安全边界大部分还是得靠操作员自己搭。
维度二:身份与网络暴露,Gateway 不是普通端口,而是控制平面
多渠道接入让 OpenClaw 同时面对两套身份体系:一套是互联网侧的 bot token、webhook secret、群组身份;另一套是本地侧的 WebSocket、设备配对、scope 授权。
这也是为什么我一直强调:Gateway 不能被当成“本地小工具开的一个端口”,它更像一个高价值控制平面。
官方的 Trust 文档↗ 也把“Identity risks”“Gateway exposure”“Misconfiguration”明确列为核心风险类别。
这里最重要的洞察只有一句:“只监听本地”不等于“不会被远程利用”。 浏览器、反向代理、本地服务之间的交互,本来就充满容易被误判的跨域通道。ClawJacked 和 localhost 爆破,已经把这点说明得很清楚了。
维度三:提示词注入,数据和控制之间那堵墙并没有想象中稳
在传统安全模型里,数据是数据,命令是命令,两者应该有清晰边界。
可在 OpenClaw 这类系统里,Agent 读取网页、文档、邮件、说明文档时,很难从底层可靠地区分:哪一段是给我分析的内容,哪一段其实在偷偷命令我做事。
这类风险之所以被放大,至少有三个原因:
- Agent 真的能干活。命令执行、文件操作、消息发送都是真实能力,所以注入后果不是“说错一句话”,而是“真的做错一件事”。
- 配置面和命令面曾经出现过授权边界漏洞,比如
/config的 owner-only 校验缺陷,这让注入成功后的提权空间变大。 - ClawHub 的投毒事件已经证明,攻击者确实会把文档本身当成攻击载体。这不是纸上谈兵。
所以我越来越相信一个判断:不能把防线只押在 prompt 上。 真正要拦的,应该是执行出口,比如网络外发、系统调用、凭据读取。只要碰到这些动作,就得有物理层面的阻断或强制人工确认。
维度四:数据隐私,“自托管”不是天然安全的同义词
“完全自托管”“数据都在本地”,听上去很有安全感。但其实并不是。
OpenClaw 里真正有价值的数据,至少包括:
- 对话与转录(transcripts JSONL):历史上出现过默认权限过宽问题;
- 工作区文件:包括
MEMORY.md这类持久化上下文; - 渠道和模型凭据:Bot token、API keys,以前就出过写进日志的事故;
- 运行日志:很可能包含完整请求、响应和上下文。
恶意 Skills 和信息窃取木马已经被观察到会专门“狩猎” .openclaw 配置目录。Moltbook 那 150 万个令牌泄露,则进一步证明:你本地守得再严,只要第三方集成的安全水位偏低,整个边界还是会被拖下去。
所以隐私防护不能停留在“我用了自托管”这句安慰话上,而要落实成具体动作:目录隔离、权限收紧、日志脱敏、凭据不落盘或加密存储、第三方集成最小授权、技能来源白名单化。
风险清单
| # | 风险点 | 可能症状 | 常见根因 | 建议修复 |
|---|---|---|---|---|
| 1 | Gateway 端口公网暴露 | 陌生人能控制你的 AI | 绑定 0.0.0.0 且无认证 | 绑定 loopback + 强 token |
| 2 | ClawHub 恶意 Skills | 凭据被盗、系统变慢 | 缺乏供应链审计 | 白名单制 + 隔离环境测试 |
| 3 | 浏览器充当“内鬼” | 浏览恶意网页后 Gateway 被接管 | WebSocket 跨域信任 + loopback 速率限制豁免 | 升级 + 强密码 |
| 4 | 反向代理伪装本地 | 公网请求绕过认证 | 错误的 X-Forwarded-For 信任配置 | 正确配置 trustedProxies |
| 5 | AI 删除重要文件 | 文件 / 邮件消失 | 上下文压缩丢弃安全约束 | 高危操作人工审批 |
| 6 | 系统提示被提取 | 内部配置泄露 | 提示词注入防护不足 | 最小权限 + 敏感信息不入 prompt |
| 7 | 记忆被投毒 | AI 持续异常决策 | 恶意指令写入持久化记忆 | 定期审计 MEMORY.md |
| 8 | 假安装器 / 钓鱼 | 安装后中木马 | 误信搜索引擎或仿站 | 只从官方渠道安装 |
| 9 | 第三方集成泄露 | 令牌被批量窃取 | 第三方平台安全水位低 | 最小权限授权 + 定期审计 |
| 10 | 工作区自动加载插件 | clone 仓库即执行恶意代码 | 缺乏显式信任步骤 | 升级到 2026.3.12+ |
如果你现在就在用 OpenClaw,先做这 5 件事
- 把 Gateway 监听地址收回到 loopback,不要直接暴露公网。
- 轮换旧 Token,尤其是曾经暴露过 Web 控制面的实例。
- 关掉不必要的高危工具权限,让命令执行、文件写入、外发网络都走审批。
- 对 Skills、安装包和第三方集成做来源白名单,不要把“热门”当成“可信”。
- 定期检查日志、转录和
MEMORY.md,确认没有把凭据、敏感上下文和脏指令悄悄留在本地。
这一篇想留下什么
这一篇把 OpenClaw 从 2025 年底到 2026 年 3 月的主要安全事件,尽量串成了一张能看懂的地图:9 个核心 CVE、3 类供应链攻击、2 起社会工程案例、4 种 AI 失误形态,以及第三方生态的连锁风险。
如果你一路读下来只记住一件事,我希望是这句:OpenClaw 的问题,不只是“修完几个 bug 就能放心用”那么简单。 更需要正视的是,AI Agent 一旦拿到系统权限,小失误就很容易被放大,最后跨到系统层面。
原理讲到这里,差不多该落到动作上了。下一篇《OpenClaw 安全加固实战》,我会把安装前、配置中、运行后的检查项拆成一张清单。