
AI帮我造博客(六):零设计基础做首页——从蒙眼指挥到截图驱动的三轮进化

📖 本文是「AI帮我造博客」系列第六篇。上一篇:AI帮我造博客(五):前端框架选型——为什么是 Next.js?
上一篇选定了 Next.js 做底座。骨架搭好了,接下来该让它"好看"了——这件事,远比我想象的难。
TL;DR
首页设计前后折腾了三轮,每一轮的突破都是被大模型的能力进化推着走的。最后我摸出一条路子:AI 生图定调并产出切图素材 → 多模态模型逆向提取规范 → 截图驱动迭代。零设计基础,搞出了一个自己还比较满意的"科幻舰桥"首页。
先看结果——
旧版(25 年初,早期模型直出):
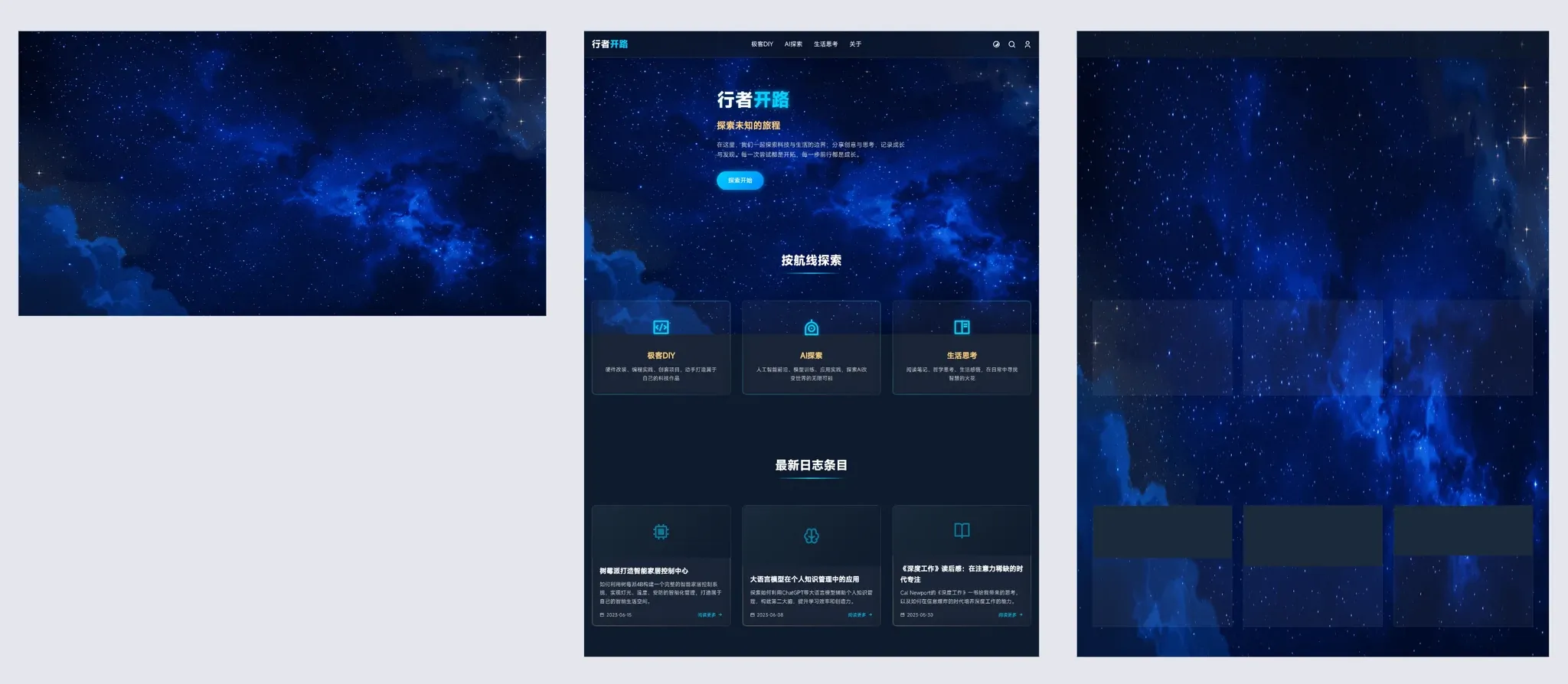 /// 旧版首页 ///
/// 旧版首页 ///
最终版(多模态工作流产物):
 /// 科幻舰桥风格的博客首页 ///
/// 科幻舰桥风格的博客首页 ///
1. 第一轮:蒙着眼睛指挥画画——纯文字时代的盲人摸象
回过头看,第一轮翻车的原因不全是"模型太笨"。病根在我自己身上:我试图用文字精确描述画面,然后指望纯代码模型凭空把它渲染出来。为了这事,我甚至折腾出两份走极端的"设计文档",每一份都是一种典型的错误示范。
1.1 两个极端:人体 CSS 编译器 vs. 科幻小说家
2025 年初,拿着刚搭好的 Next.js 脚手架准备动手做首页。为了向纯文字驱动的 AI 传达审美,我先后试了两种方向完全相反的写法。
第一种:当"人体 CSS 编译器"
我一开始想要一种有岁月感的"航行日志"风格。怕 AI 配色翻车,就想着:行吧,我自己查好所有参数,逼着自己手写了一份硬核到骨子里的《航行日志重构规范》:
节选自《航行日志前端设计系统 v2.0》:
- 材质与质感:铜制面板依赖
background: linear-gradient(145deg, #E6C248 0%, #D4AF37 50%, #B8941F 100%)附带白/黑的高亮与内阴影层。- 动效缓动:严格定义如精密仪器般的回弹,参数锁定
cubic-bezier(0.68, -0.55, 0.265, 1.55)。- 间距系统:基于 8px 网格,建立从
--space-1到--space-24的全局变量。
写这些东西让我极其痛苦——我压根不知道 cubic-bezier(0.68, -0.55, 0.265, 1.55) 渲染出来长什么样。一个不是设计出身的人,在各种设计网站上东抄一个 HEX 值(网页颜色代码)、西凑一个缓动函数,然后祈祷它们组合起来别太丑。
结果当然不行。就算把这些冷冰冰的参数喂给模型,它也没法凭几个渐变色值就变出"有厚度的老物件质感",最终页面又干又僵。
第二种:当"科幻小说家"
死背参数行不通,我推翻重来,转向"深蓝舰桥"方向。这次我反过来——扔掉所有代码,像写电影场景一样大段描述意象:
节选自《深蓝舰桥核心设计方案》:
- 上层全景视界:宽幅大背景占据屏幕顶部。窗外是浩瀚深蓝的星海或数字洋流,Slogan 有着发光的故障艺术漂浮效果。
- 中层战术仪表盘:模拟控制台,中屏展示最新文章,边缘搭配全息闪烁的扫描光效,右侧是像声呐一样的动态律动感。
- 底层操作甲板:不要简单超链接,要做成带有金属厚度和光亮度极强的物理按键……
我把"数字罗盘"、"星海"、"全息投影"这些词像调料一样使劲往里撒。如果拿这些去找一位影视级原画师,大概率能出很惊艳的概念图。但代码模型不是原画师。
1.2 早期模型表示:"臣妾做不到啊"
带着那份赛博味拉满的《深蓝舰桥》,我满怀期待地扔给了当时的旗舰代码模型。
结果……就是你看到的那张旧版首页图片。说好的炫酷深海指挥中心控制台呢?怎么生成成了带有五毛钱紫色特效边框的网管系统后台。
问题出在纯文字模型做"跨模态转译"时的天花板:
- 靠词频平均来"理解"审美。它读到"科幻"、"星际 HUD(平视显示器,常用于游戏界面的信息面板)",并没有真的仰望过夜空。它做的事大概率是去 GitHub 上找高频出现的科幻 UI 搭配,于是大面积紫色渐变、到处都是亮瞎眼的发光阴影就汹涌而来。它没法把我那些散文段落换算成审慎克制的 CSS。
- 长文档导致意图遗忘。写了上百行的概念设计说进去,模型在写底部组件时,早已忘了开头要求的是"神秘清冷"的色调。
- 纯文字信道,两边都在盲猜。我说"科幻全息亮蓝",模型说"好的"——但它不会用眼睛去验证自己写出的东西在浏览器里渲染成了什么颜色。我俩其实谁也看不见对方眼中的那个"蓝"到底长啥样。
1.3 越改越崩的拉扯循环
更折磨人的是后面的迭代。每次看到页面不对劲,对话就变成了这样:
我:"顶部的渐变太生硬了,能克制一点吗?"
AI:"好的,我已经去掉了渐变,改为纯色背景。"(……我说的是克制,不是删掉啊。)
我:"不是去掉,是让过渡更柔和,参考设计文档里的深空感。"
AI:"明白了,我增加了星光粒子动画效果。"(谁让你加粒子了……)
每一轮你都觉得自己说得够清楚了。每一轮 AI 都在合理范围内还你一个"差那么一口气"的方案。十轮下来,页面没有在变好,只是在不同方向的"差一口气"之间来回晃。
几天拉扯下来,我终于意识到:这不是 AI 的错,也不是我词汇量不够。是工作方式本身有结构性缺陷——你在用文字描述色彩,用语言传递布局,本质就是蒙着眼睛指挥别人画画。更复杂的文档、更凶狠的 Prompt(AI提示词指令),根本跨不过"美是需要用眼睛看的"这条鸿沟。
2. 第二轮:同一份文档,模型换代了——终于能出活了
2025 年下半年,GPT-5 发布,紧接着 Gemini 3 也来了。
我做了件很简单的事:把之前那份文档原封不动地扔给新模型。
出来的东西,比以前好了一个档次。
2.1 新模型强在哪
几个肉眼可见的差异:
- 长上下文的指令遵循靠谱了。100 行设计文档,从头到尾保持一致。你在第 3 行定义的色板,不会在第 80 行的组件实现里被遗忘。
- 概念理解不再粗暴。"科幻"不等于紫色渐变了。它能分辨"克制"、"工业感"、"磨砂玻璃"分别对应什么样的 CSS 实现。
- 开始能"看图"了。你可以把页面截图扔给它,它能指出"哪个区域有什么问题"。以前它是闭着眼睛猜你的形容词,现在至少睁开了一只眼。
2.2 但我依然陷在"抽卡"模式里没出来
模型能力虽然上来了,新的问题反而暴露得更清楚:写一份合格的设计文档这件事本身,对没有设计背景的程序员来说,就是一堵过不去的墙。
总结一下这个阶段的真实体感——
我的《深蓝舰桥》之所以还算能用,不是因为我有设计直觉,而是因为我花了很多时间在 Dribbble、Behance 上找参考,一个一个抄 HEX 值,硬凑出来的。可即便这样,每次把文档扔进去,体验本质上也跟抽卡没区别:运气好了,出来的效果还凑合;运气不好,满屏碎片。我名义上在做前端开发,实际就是在拿算力碰运气。
更要命的是,这个"卡池"没法复用。如果让我换一种风格——比如极简留白或新拟态——从零写设计规范,我大概率只能憋出几句干瘪的废话。
到这儿我想明白了一件事:既然我是个没设计基础的程序员,就不该强行把脑子里模糊的画面"降维"成文字文档,然后指望机器抽中我要的那张卡。这条路注定失控。
有没有更直接跨过这道鸿沟的办法?
3. 第三轮:AI 生图来了——直接跳过"写文档"这步
其实在 Nano Banana 之前,Midjourney、Flux 等生图模型已经很强了。但旧时代的提示词像一门需要单独学习的"咒语":由于自然语言理解能力有限,你需要堆砌各种固定格式的艺术标签才能出好图。如果你用正常的长句去"聊天",它往往抓错重点。
真正的转折,发生在 Nano Banana 这一类自然语言理解极强的生图模型出现之后。
那次飞跃的核心在于:你不需要背咒语了,直接用日常说话的方式描述你想要的画面,它就能精准渲染出来。
3.1 用生图替代设计文档来定调
想通这一层之后,我回头看自己当初那两份"废案",突然觉得哭笑不得——
那份被我扔掉的《深蓝舰桥》设计文档里堆满的意象描述,什么"星舰舰桥指挥台、星海背景、克制的暗蓝色与青色辉光"——交给代码模型时确实是废话,可放到今天,这不就是一段画面感极强的生图 prompt 吗?
于是我也不碰任何 CSS 概念了,直接拿大白话的意象去给生图模型"出概念":
"一个深色科技主题的博客首页,模拟飞船舰桥控制台。左侧有数据监控卡片,中央是文章列表。底部有带金属质感的发光导航按键。整体深蓝色调配低对比度青色,保持工业感和克制的留白。"
十来秒,四张高质量概念图就回来了。没有一行代码,没有一个 HEX 值(网页颜色代码),但这四张图在视觉上直接秒杀了我之前那份写了两天的设计文档。
我终于不用在脑子里痛苦地拼凑"这个金属边框到底配什么 RGB 和透明度才不会显得廉价"了。我只需要当个甲方——看图、选图、提意见,然后让 AI 去操心参数。
选出最对味的那张概念图之后,第二步来了:回到多模态大模型(比如 Gemini 3)。我把参考图贴给它,让它逆向拆解:
"请以资深 UI 设计师的视角,从这张参考图中提取完整的设计规范:
- 色板:主色/辅色/强调色,精确到 HEX 值
- 排版:标题/正文/间距的层级关系和字体回退
- 组件风格:卡片样式、发光效果、模糊值、按钮阴影的 CSS 参数
- 布局韵律:对齐方式和留白比例
导出为一份design-system.md文件。"
还记得第一轮里我逼着自己手写的那份令人头皮发麻的《航行日志 v2.0》吗?那些渐变参数、缓动曲线、间距变量——现在全部交给多模态 AI 从图片里"倒推"出来。而且因为它是基于一张已经在视觉上成立的图来逆向提取的,导出的设计规范天然具备内在一致性——色彩搭配、间距比例、组件风格彼此呼应,不像我手拼的那份到处打架。
你可以感受一下 AI 仅凭首页设计图,逆向提取出的一套能直接用来写 Tailwind CSS(一种流行的前端样式框架)的硬核视觉参数(节选自其生成的 design-system.md):
🎨 色彩系统 (Color Palette)
- 主背景色 (Primary Deep):
#060B14(深空蓝黑,提供极暗且深邃的基底)- 次要高亮色 (Secondary Cyan):
#00DCFF(亮青色,用于高亮标题与控制指令)- 文本中性色 (Neutral Text):
#E0E7FF/#94A3B8(冷白搭灰蓝,保证极暗环境下的阅读舒适度)✨ 物理质感与发光特效 (Glassmorphism & Glow)
- 控制台面板基础材质: 半透明深色
rgba(15, 23, 42, 0.6)叠加毛玻璃背景模糊backdrop-filter: blur(12px);- 赛博边界发光阴影:
box-shadow: inset 0 0 15px rgba(0, 220, 255, 0.1), 0 0 20px rgba(0, 0, 0, 0.5);- 文字霓虹辉光:
text-shadow: 0 0 10px rgba(0, 220, 255, 0.8);
这就是视觉大模型带来的降维打击。比起第一轮里我像个科幻小说家一样用大段废话描述“沉浸感”,这几句冷冰冰的 HEX 参数和 box-shadow 坐标,才是代码模型真正听得懂的语言。几个参数砸进去,一个深黑荧光的科幻舰桥质感立刻就立住了。
3.2 绝对刚需:让 AI 顺手把细节素材图做了
只凭 CSS 当然拼不出复杂的科幻网页。诸如深渊星空背景图、真实金属纹理、或是文章配图等细节,靠纯写代码去硬算是不现实的,浏览器渲染性能也会被拖死。
这时候,别忘了生图模型强大的“切图制作”能力。这其实是整个环节的另一出重头戏——你不但可以用它出概念图,还可以直接将概念图转化为网页实际可用的富媒体素材。
比如前文那张舰桥概念图,遇到无法用 CSS box-shadow 模拟的复杂星云时,你可以直接裁剪概念图里的星空背景,然后通过 AI 扩图或者局部重绘工具,将其生成一张横向的 1920px 宽超大壁纸贴图。把它丢进 Next.js 的 public 文件夹下做底层物理背景,这比任何纯 CSS 渐变都灵动百倍,且落地成本无限趋近于零。
3.3 可选的保险步骤:用原型工具校准布局
(小白别怕,这是个可选项。如果你不会用任何设计软件,完全可以跳过这步。)
这里有一个值得注意的小陷阱——生图模型出的毕竟是"不讲布局逻辑的艺术画"。某些视觉上很有张力的排版,放到真实的 CSS Box Model(网页元素的排版盒子机制)里,经常存在随意堆叠、没有代码嵌套逻辑和层级观念的问题。如果你直接让代码模型去实现那张图,由于缺乏结构化的骨架梳理,生成的代码可控性偶尔是会翻车的。
这时候,如果你愿意多花一步,引入像 Visily、Uizard 或 Figma 这样的原型工具作为缓冲层,效果会好很多。
最经典的做法是:把你满意的 AI 概念图扔进 Visily(一个专为快速原型打造的工具),利用它自带的 AI Scan UI 识别能力,将位图瞬间"解构"成具有明确边界、清晰层级、可自由拖拽的矢量 UI 原型。或者如果你对 Figma 比较熟,也可以根据 design-system.md 的颜色和间距参数,快速拉一个低保真线框来定位元素。
不过必须说清楚:即便你完全不用这些工具,这套"生图→代码"的流程依然跑得通。不用 Figma 等工具时,多模态模型照样能凭视觉分析直接从原图硬写出框架代码。两者的区别在于:省略这个"切图校验"环节,面对复杂的高级布局时,代码生成可能会出现容器不严格对齐、随意发挥的情况;而如果给这段流程套上原型工具这层护栏,前端工程化的严谨度和稳定度会高出不少。
3.4 截图驱动迭代:终于不用蒙着眼睛改了
基于 AI 提取的设计规范,让代码模型生成第一版前端代码。浏览器里跑起来之后,少不了各种细节偏差——间距不对、某个发光效果太抢眼、层级不够分明。
在第一轮,到这一步是噩梦。但现在有了多模态模型的视觉能力,修改方式变了:
- 截图:把浏览器渲染的页面截下来
- 标注:用最简单的红圈画出问题区域
- 写极简指令:
"截图里标的三个问题:
① 导航栏的口号文字跟背景融在一起了,对比度不够
② 左侧统计面板和中间内容区的上边缘没对齐
③ 底部按钮发光太强,不够克制
只改这三处,其余不动。"
模型能"看到"你看到的东西。它理解"融在一起"指的是哪两个元素,"不对齐"偏了几个像素,"太强"强在什么地方。它不再盲猜你的形容词了——就像一个坐在你旁边的前端同事,和你一起盯着同一块屏幕在排查问题。
这个反馈循环通常 3–5 轮就能把一个组件打磨到位。和第一轮动辄十几轮的漂移式拉扯比,效率差了一个数量级。
4. 工作流全景:每个 AI 只干它最擅长的事
从第一轮的“纯文字盲猜”,到依靠写设计文档的“抽卡”,再到直接拿 AI 生图进行“逆向工程”,那些踩过的坑最终帮我沉淀出了一套工作流。核心思路很简单:不要把大模型当成万能黑盒,而是把不同能力的 AI 组合成一条各司其职的流水线,人只负责做判断和选择。
阶段 1:概念定调(用生图模型,不写代码)
工具:Nano Banana 等自然语言理解强的生图模型
做什么:用一段自然语言描述你要的网页风格,生成 3–5 张概念图。
你的角色:看图选图。挑出最接近心中画面的那张(或从不同图里各取所长,组合描述后再生成)。
几个经验:
- 不需要设计术语。"像星舰控制台"、"暗色为主、青色点缀、别太花"这样的大白话就行。
- 多生几轮。生图成本极低,十秒一张,别吝啬。
- 这一步的产出不是代码,是视觉共识——你和后续的 AI 终于在"什么叫好看"上对齐了。
阶段 2:设计规范提取(用多模态模型逆向拆解)
工具:Gemini 3 / GPT-5 等有强视觉理解能力的模型
做什么:把选定的概念图发给大模型,让它以 UI 设计师的视角,从图像中逆向提取出设计规范——色板、字体、间距、组件风格、布局规则。
你的角色:审阅规范并做取舍。比如提取出的强调色太多了,你手动砍到两种。
几个经验:
- 把这份规范当合同看。后续所有迭代都得遵守这个合同,不许模型在风格上漂移。
- 明确写出"禁止项":不要霓虹色、不要大圆角、不要弹跳动画。在设计上,"不要"往往比"要"更有用。
阶段 3:视觉素材投产(抠素材与切图)
工具:Photoshop 的 AI 扩图功能 / 各类具备局部重绘的生图模型 / 抠图背景消除工具
做什么:纯 CSS 渲染不出的复杂图层(如星空底纹背景、质感厚重的机甲纹路饰边、半透明全息徽标贴纸),利用生图模型针对性生成或二次裁切出局部原画素材,保存为透明 PNG 或者 WebP 壁纸。
你的角色:裁切、扩图、把关品质,最后将它们分发到项目的静态资源目录里当作真实的物理贴图使用。
阶段 4:静态原型生成(先验收气质,再接入数据)
工具:Gemini 3 / Claude 等代码能力强的模型
做什么:基于前面提取出的 CSS 设计规范,同时引入刚刚准备好的贴图图片素材,让模型生成纯静态的 HTML/CSS 页面。此时用假数据占位,不接 API。
你的角色:在浏览器里只看三件事——信息结构对不对、视觉气质(结合图像贴图后)对不对、响应式骨架对不对。
几个经验:
- 先做静态原型再接真实数据,是因为接了数据之后改布局的成本会陡增。
- 一次只验收一个区块(导航 → 主内容区 → 侧边栏 → 底部),别想一口气看完整页。
阶段 5:截图驱动迭代(Visual Debugging 视觉调试主循环)
工具:任何支持图片输入的多模态大模型
做什么:运行项目 → 截图 → 标注问题 → 发给大模型 → 拿到修改 → 应用 → 再截图。每轮只改一个组件。
你的角色:截图、画红圈、写极简指令。
反馈模板:
"只改 [组件名],不动其他区域。设计规范合同不变。
当前问题:[截图 + 标注]
① [具体问题 1]
② [具体问题 2]
修改目标:[能量化就量化,比如'边框透明度降到 30%'、'间距增加 8px']"
几个经验:
- 形容词可以有,但要用参数钉住。你说"太亮",得配上"对比度降低到 4.5:1";说"不够克制",得配上"发光半径从 8px 缩到 2px"。
- 严格控制修改范围。每轮必须写"只改 X,不动 Y",否则 AI 经常会顺手把你已经验收过的区域给重构了。
阶段 6:工程收口(接 API + 做验收清单)
工具:代码模型 + 你自己的工程判断
做什么:静态原型打磨到位后,接入真实数据,做工程收口。
你的角色:让 AI 当"审查员"而不是"重写者"——只输出风险清单,不重写代码。
审查清单 Prompt:
"请只输出风险清单,不要重写代码:
- 缺失哪些环境变量或配置文件
- 哪些链接可能 404
- loading / error / empty 状态是否覆盖了
- 移动端在哪些宽度断点可能崩
- 可访问性:对比度、可点击区域、键盘导航"
5. 三轮复盘:本质是大模型能力进化的缩影
回头看,同一个需求("做一个科幻风格的博客首页"),在三轮里的实现逻辑完全不一样:
| 第一轮(25 年初) | 第二轮(GPT-5 / Gemini 3) | 第三轮(生图 + 多模态组合) | |
|---|---|---|---|
| 核心瓶颈 | 模型能力不够,指令遵循差 | 人写不好设计文档 | — |
| 设计意图传达 | 人工写 100 行设计文档 | 同一份文档,模型终于能遵循 | AI 生图定调 → 模型自动提取规范 |
| 代码生成质量 | 廉价渐变、风格漂移 | 明显提升,但受限于文档质量 | 以视觉为锚,精准匹配 |
| 迭代方式 | 纯文字来回拉扯 | 可以截图反馈 | 截图驱动 + 参数锁定 |
| 人的角色 | 写文档 + 猜形容词 | 写文档 + 看图反馈 | 看图选图 + 审规范 + 画红圈 |
最核心的变化是:我干的活,从"描述"变成了"判断"。
第一轮,80% 的精力花在写设计文档、斟酌形容词、试图用语言传递"我脑子里的那个画面"上。到第三轮,80% 的精力变成了看图、选图、画红圈——这些都是人类天生就擅长的感性判断,而不是逆着直觉做的文字翻译工作。
最终这条流水线里,每个角色干的都是自己最擅长的:
- 生图模型:把模糊的意象变成清晰的画面(想象力放大器)
- 多模态大模型:从画面中提取规范、理解视觉差异(视觉翻译器)
- 代码大模型:把规范变成能跑的前端代码(工程执行器)
- 我:在关键节点做"选哪个"和"哪里不对"的判断(决策者)
不是把 AI 当万能黑盒,而是把不同能力的 AI 组成一条各司其职的流水线——我觉得这才是"AI 辅助开发"真正该有的样子。
6. 航海日志
| 本次航线 | 遇到的暗礁 | 带回的货物 | 下一站 |
|---|---|---|---|
| 首页设计(三轮迭代) | 文字无法传递审美;早期模型指令遵循力不足 | 实景演练 AI 工作流:生图定调并产出切图素材 → 视觉规范验证提取 → 截图驱动代码迭代 | 文章页设计 |
搞定了博客的“门面”,接下来就该深入真正的核心内容区了。在下一篇,我们将探讨文章页的详细设计,敬请期待!
📚 AI帮我造博客系列导航
上一篇:AI帮我造博客(五):前端选型——为什么是 Next.js?
下一篇:AI帮我造博客(七):文章页设计,本系列持续更新中,敬请期待下一篇!