
AI帮我造博客(九):给博客装个后端——Strapi 建模、配置与踩坑实录
TL;DR:用 Strapi 给博客建内容模型——Article 的每个字段为什么这么长(摘要为什么要单独存、分类为什么改成多对多、SEO 标题为什么得独立于正文标题),外加三个真实的坑:本地连不上数据库其实是 AI 默认你在 Docker 里跑,Strapi 的开发态和生产态得打两个镜像。想直接抄模型,跳到「Article:每个字段都有理由」那节就够。
前端说得差不多了,再来说后端。
本系列文章第八篇里我们把文章页的渲染链路打通了:AST 提目录、Shiki 高亮代码、Tuner 对齐音乐播放器。但那些全是假数据,硬编码在前端。
真要写博客,后端才是放真实内容的地方,一个能录入文章、存储内容、对外吐 API 的系统。
本系列文章第四篇里我对比了 Strapi、Payload、Directus 三个 Headless CMS,最终选了 Strapi(社区最大、踩坑时能搜到答案)。
这篇讲的不是"为什么选 Strapi",而是选完之后怎么用:怎么给博客设计内容模型,为什么每个字段长成现在这个样子,以及踩了哪些坑。
安装:一行命令,别想多
npx create-strapi-app@latest my-blog --quickstart--quickstart 是关键。不带它,安装过程会问你用 TypeScript 还是 JavaScript、数据库选 MySQL 还是 PostgreSQL——第一次跑 Hello World,这些全是噪音。
--quickstart 默认用 SQLite(一个内嵌的文件数据库,零配置),装完直接启动,浏览器弹出 localhost:1337/admin,创建管理员账号就能进后台。
Content-Type:你的内容长什么"形状"
进了后台,第一件事是定义内容模型。Strapi 叫它 Content-Type。
你可以把它理解成数据库建表——但比建表高级。你在这里定义的字段,Strapi 会自动帮你做三件事:
- 后台生成对应的录入表单(编辑在后台填写时看到什么)
- 数据库创建对应的表结构
- API 自动暴露对应的 JSON 接口
换句话说,你定义一次模型,编辑体验、存储结构、API 接口三样全有了。这才是 Headless CMS 的核心价值——不用写 CRUD,不用写接口,不用写后台表单。
Strapi 有两种模型:
- Collection Type(集合):存多条数据。文章、分类、标签、作者都是集合。
- Single Type(单条):全站只有一份。比如站点配置——网站名称、SEO 默认值、站长验证码这些,只需要一条记录。
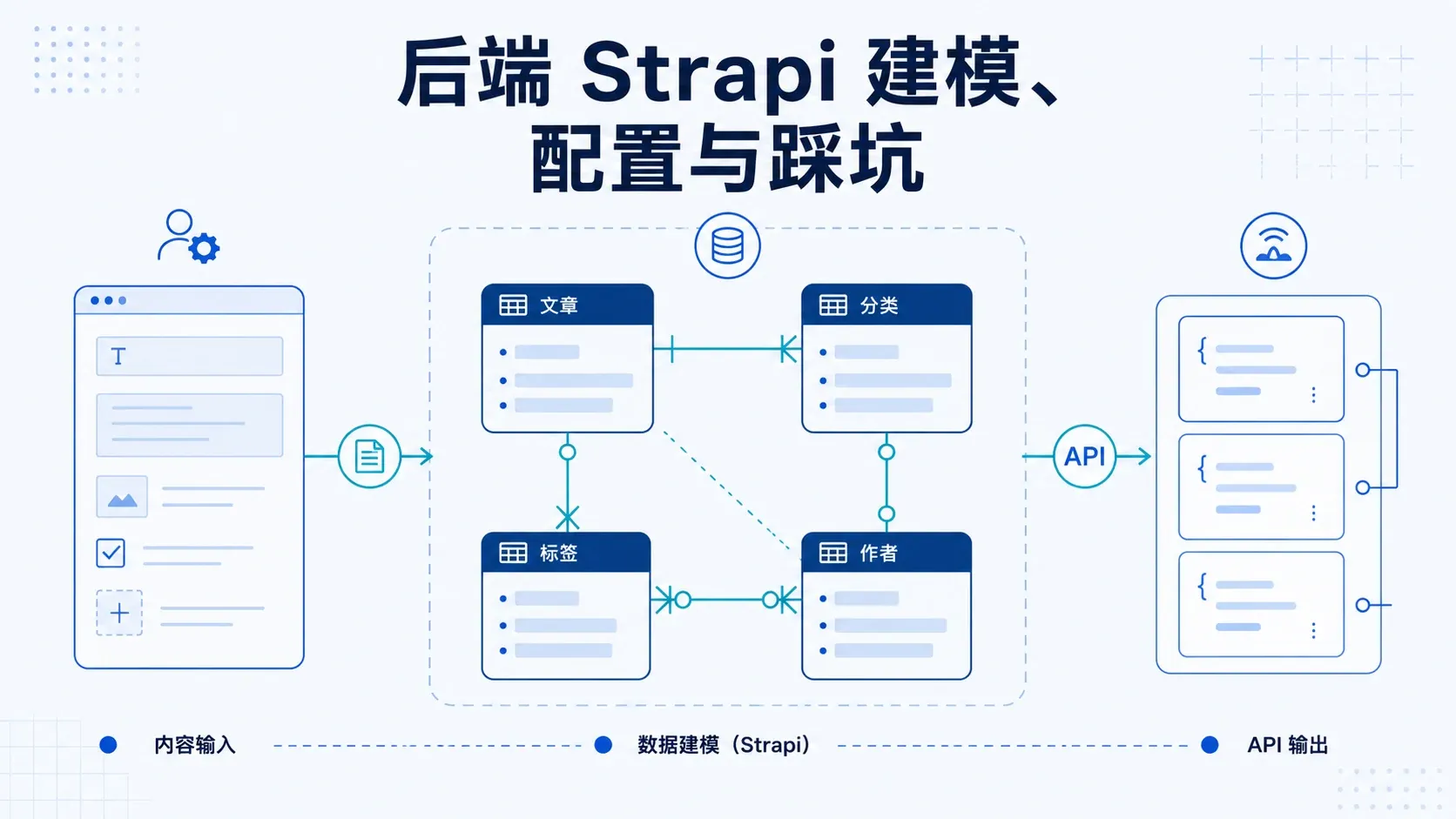
整体架构:博客需要几种内容模型
在开始建模之前,我先列出了博客需要哪些数据实体:
Collection Types(存多条数据):
- Article:文章,博客的核心
- Category:分类,对应我博客的五大栏目(折腾手记、造点东西、投资笔记、做点音乐、想点事情)
- Tag:标签,比分类更细粒度的组织方式
- Author:作者,虽然现在只有我一个人写,但独立建模有扩展性
Single Type(全站只有一份):
- SiteSettings:站点配置,存网站名称、默认 SEO 配置、各大搜索引擎的站长验证码
一个作者写多篇文章;一篇文章可以属于多个分类、打多个标签。
下面逐个讲每个模型为什么这么设计。
Article:每个字段都有理由
这是最复杂的模型。我让 AI 帮我出一份字段清单,约束是:
"技术博客,需要 SEO 友好,列表页加载要快,支持置顶和分类,正文用 Markdown。"
AI 给了第一版,我逐个字段审了一遍,砍了几个没用的,补了几个它漏掉的。最终定稿:
Article (Collection Type)
├── 基础字段
│ ├── title Short Text, 必填
│ ├── slug UID, 关联 title
│ ├── excerpt Text
│ ├── content Rich Text (Markdown)
│ ├── coverImage Media, 单张
│ └── isPinned Boolean
├── 关系字段
│ ├── categories Relation → Category (多对多)
│ ├── tags Relation → Tag (多对多)
│ └── author Relation → Author (多对一)
└── SEO 字段
├── metaTitle String
├── metaDescription Text
├── ogImage Media, 单张
└── canonicalUrl String为什么这么设计?
title 和 slug:一个给人看,一个给 URL 用
title 是你在后台录入时写的标题,比如"Strapi 入门踩坑记"。
slug 是 URL 里代表这篇文章的那串字符,比如 strapi-getting-started。Strapi 的 UID 字段类型可以关联 title,你填完标题它自动生成 slug。
为什么不直接拿 title 当 URL?因为中文标题在 URL 里会变成一长串 %E4%B8%AD%E6%96%87,丑,而且对 SEO 不友好。
真实例子:我博客里这篇文章——
title:教 AI 写工作月报:从一次性投喂到节点化工作流,再到 Skills 模块化改造slug:ai-monthly-report-workflow-to-skills
前端最终生成的 URL 是 /posts/ai-monthly-report-workflow-to-skills,干净可读。
excerpt:为什么摘要必须单独存
这个字段容易被忽略。AI 第一版没给我加,我自己补上的。
道理很简单:首页的文章列表需要显示每篇文章的简介。如果没有 excerpt,前端就得从 API 拉完整的 content(正文可能几万字),然后自己截取前 200 字。
一个列表页 10 篇文章,每篇拉几万字的正文——API 响应直接膨胀十倍。
单独存一个 excerpt,列表页只拉这个字段,正文留到用户点进详情页时再拉。接口轻了,页面快了。
真实例子:月报那篇文章的 excerpt 是——
每月写月报让人头大?本文记录了我不仅设计了一套节点化 AI 工作流来自动生成图文月报,还在 Antigravity Skills 推出后进行了模块化改造的完整折腾过程。
首页列表展示这段,够了。6000 多字的正文留给详情页。
content:Rich Text 选 Markdown
Strapi 的富文本字段有两种模式:可视化编辑器(类似 Word)和 Markdown。
我选 Markdown,因为前端已经有完整的 Markdown 渲染管线了——本系列文章第八篇里搭的 AST 解析 + Shiki 高亮 + 自定义组件,这套东西就是渲染 Markdown 字符串的。选可视化编辑器反而要额外处理 HTML 到 Markdown 的转换。
coverImage:单张,不是多张
Strapi 的媒体字段有 Single 和 Multiple 两种。封面图显然只需要一张。
但有个要注意的:Strapi 默认把上传的文件存在 public/uploads/ 目录里。本地开发没问题,一旦用 Docker 部署,容器重启文件就没了。后面部署时我们得把这个目录挂载到外部卷——这个坑后面再说。
isPinned:一个布尔值省掉一套置顶系统
首页要支持置顶文章。最简单的做法:加一个 isPinned 布尔字段,前端查询时先按 isPinned 降序,再按发布时间降序。一个布尔值搞定,不用搞什么"置顶权重""置顶队列"。
categories 和 tags:关系怎么选
这里有个关键设计决策:文章和分类之间是多对多还是一对多?
一对多的意思是:一篇文章只能属于一个分类。多对多的意思是:一篇文章可以同时属于多个分类。
我一开始选了一对多——感觉一篇文章归到一个栏目就够了。但后来想了想,还是改成多对多吧。
这个改动在开发阶段很简单,在 Content-Type Builder 里把关系类型重新选一下就行。但如果已经上线有数据了,改关系类型意味着要写数据库迁移脚本,代价完全不同。
所以建模这件事,前期多想五分钟,后期少改五小时。
tags 同理,多对多。
author 是多对一:一个作者写多篇文章,一篇文章只有一个作者。
真实例子:月报那篇文章——
categories:[折腾手记](大部分文章归一个分类就行)tags:[AI探索, SKILLS, 工作效率](打了三个标签)author:舸扬
多对多的设计让我可以灵活组织内容。哪天写篇"用 AI 搭建投资看板",我可以同时归到"折腾手记"和"投资笔记"两个分类。
SEO 字段组:给人看的标题 ≠ 给搜索引擎看的标题
AI 提醒了我一个我没想到的设计:metaTitle 必须独立于 title。
为什么?假设我写了一篇文章,给读者看的标题是"今天我把数据库删了"。但搜索引擎需要的是:"PostgreSQL 误删数据恢复方案 - 舸扬号"。
如果只有一个 title 字段,你只能二选一:要么对读者友好,要么对搜索引擎友好。拆成两个字段,各管各的。
ogImage 是社交分享时显示的图片(比如你把文章链接发到微信群里,预览卡片上的图)。canonicalUrl 是告诉搜索引擎"这篇文章的原始地址在这里",防止转载网站抢你的 SEO 排名。
真实例子:月报那篇文章——
title:教 AI 写工作月报:从一次性投喂到节点化工作流,再到 Skills 模块化改造metaTitle:教 AI 写工作月报:从工作流到 Skills 改造实践metaDescription:分享如何设计 AI 工作流自动生成工作月报,以及从 Document-as-Orchestrator 模式迁移到 Antigravity Skills 的实践经验。
title 给读者看,长一点没关系,把副标题都带上。metaTitle 给搜索引擎看,精简了"一次性投喂到节点化工作流"这段,突出核心关键词"工作流""Skills""改造实践"。
metaDescription 更是专门给搜索结果页准备的——用户在 Google 搜"AI 写月报"时,标题下面显示的那两行小字就是它。
在 Strapi v5 中配置 Content-Type
理论讲完了,实际怎么操作?

/// strapi content-type 配置 ///
进入 Strapi 后台 → Content-Type Builder(左侧菜单)→ Create new collection type。
1. 创建 Collection Type
以 Article 为例:
- Display name 填
文章(或者填英文 Article, Strapi 会自动生成 API IDarticle) - 点 Continue,进入字段配置页面
2. 添加字段
点右侧的 Add another field,会弹出字段类型选择器:
- Text:短文本,对应
title - Rich Text:富文本编辑器,对应
content - UID:唯一标识符,对应
slug - Media:上传文件,对应
coverImage、ogImage - Boolean:布尔值,对应
isPinned - Relation:关联其他模型,对应
categories、tags、author
每个字段类型点进去后,都有配置项:
Text 字段配置(以 title 为例):
- Name:
title - Type:Short text
- Advanced Settings:勾选 Required field(必填)
UID 字段配置(以 slug 为例):
- Name:
slug - Attached field:选择
title(自动从标题生成) - Advanced Settings:勾选 Required field
Rich Text 字段配置(以 content 为例):
- Name:
content - Type:Markdown(如果你装了 Markdown 插件)或默认的 Blocks(可视化编辑器)
Media 字段配置(以 coverImage 为例):
- Name:
coverImage - Type:Single media(单张)
Boolean 字段配置(以 isPinned 为例):
- Name:
isPinned - Default value:false
Relation 字段配置(以 categories 为例):
- Name:
categories - Relation type:Article has and belongs to many Categories(多对多)
- Strapi 会自动在 Category 模型那边创建反向关系
articles

/// strapi 字段关系配置 ///
配置完所有字段后,点右上角 Save。Strapi 会重启服务器,应用新的模型定义。
3. 创建其他模型
用同样的方式创建 Category、Tag、Author、SiteSettings。下面逐个说明它们的字段配置。
Category:五大栏目的数据定义
Category 比 Article 简单得多,只需要三个字段:
Category (Collection Type)
├── name String
├── slug UID (关联 name)
└── description Text字段说明:
name:分类名称,比如"折腾手记"slug:URL 路径,比如tinkeringdescription:分类描述,可以在分类页顶部展示articles:反向关系,Strapi 自动生成,不用手动创建
为什么这么简单?因为分类是高层级的结构,基本不会频繁改动。我博客的五大栏目(折腾手记、造点东西、投资笔记、做点音乐、想点事情)在内容模型设计阶段就确定了,后面只需要在后台录入这五条数据,然后写文章时勾选就行。
配置步骤:
- Content-Type Builder → Create new collection type →
Category - 添加字段:
name:Text (Short text)slug:UID (Attached toname)description:Text (Long text)
- Save
Tag:更灵活的组织方式
Tag 和 Category 结构几乎一样,但语义不同:
Tag (Collection Type)
├── name String
├── slug UID (关联 name)
└── articles Relation (反向关系,自动生成)字段说明:
name:标签名称,比如"AI"、"Python"、"Docker"slug:URL 路径,比如ai、python、docker
Category vs Tag 的区别:
- Category:高层级、固定、互斥(一篇文章可以属于多个分类,但通常不超过 2 个)
- Tag:细粒度、动态、开放(一篇文章可以打很多标签)
配置步骤:
- Content-Type Builder → Create new collection type →
Tag - 添加字段:
name:Text (Short text)slug:UID (Attached toname)
- Save
Author:为扩展性留后路
虽然现在只有我一个人写博客,但把 Author 独立建模是好习惯——以后可能会有客座作者,或者想给不同作者展示不同的简介和头像。
Author (Collection Type)
├── name String, 必填
├── bio Text
├── avatar Media (单张)
└── articles Relation (反向关系,自动生成)字段说明:
name:作者姓名,比如"舸扬"bio:作者简介,可以在文章详情页底部展示avatar:作者头像articles:反向关系,Strapi 自动生成
为什么不直接在 Article 里存作者名字?因为那样改作者信息就得改所有文章。独立建模后,作者信息改一次,所有文章自动更新。
配置步骤:
- Content-Type Builder → Create new collection type →
Author - 添加字段:
name:Text (Short text),勾选 Requiredbio:Text (Long text)avatar:Media (Single media)
- Save
SiteSettings:全站配置的统一存储
这是唯一的 Single Type。它只有一条数据,存全站级别的配置。
SiteSettings (Single Type)
├── siteName String
├── siteDescription Text
├── defaultOgImage Media (单张)
├── googleVerification String
├── baiduVerification String
└── bingVerification String字段说明:
siteName:网站名称,比如"舸扬号"siteDescription:网站默认描述,当文章没有 SEO 描述时使用defaultOgImage:默认社交分享图,当文章没有ogImage时使用googleVerification:Google Search Console 验证码baiduVerification:百度站长平台验证码bingVerification:Bing Webmaster 验证码
为什么需要站长验证码?这些验证码要放在前端 HTML 的 <head> 里(meta 标签),用来向搜索引擎证明"这个网站是我的"。以前这些值是硬编码在前端代码里的,现在统一存在 Strapi,前端通过 API 拉取。
前端如何使用(Next.js 示例):
// app/layout.tsx
const siteSettings = await fetch('http://localhost:1337/api/site-setting')
.then(res => res.json());
export default function RootLayout({ children }) {
return (
<html lang="zh-CN">
<head>
{siteSettings.googleVerification && (
<meta name="google-site-verification" content={siteSettings.googleVerification} />
)}
{siteSettings.baiduVerification && (
<meta name="baidu-site-verification" content={siteSettings.baiduVerification} />
)}
</head>
<body>{children}</body>
</html>
);
}配置步骤:
- Content-Type Builder → Create new single type →
Site Setting - 添加字段:
siteName:Text (Short text)siteDescription:Text (Long text)defaultOgImage:Media (Single media)googleVerification:Text (Short text)baiduVerification:Text (Short text)bingVerification:Text (Short text)
- Save
本地开发连不上数据库:AI 缺少上下文背景
Strapi 快速启动用的是 SQLite——文件数据库,零配置。但部署到生产环境,SQLite 撑不住并发,得换 PostgreSQL。
我让 AI 帮我写数据库配置。它给了一份从环境变量读取 host、port、password 的 database.ts,默认值填的是 postgres:5432。
在本地跑 npm run develop,直接报错:
Error: getaddrinfo EAI_AGAIN postgresAI 让我查防火墙、查密码、查 PostgreSQL 有没有启动。折腾了大半天。
最后我盯着那个 postgres 主机名,突然明白了——AI 以为我是在 Docker 容器里跑开发环境。在 Docker Compose 编排里,数据库容器的 service 名就叫 postgres,容器之间可以互相用服务名访问。但我是在自己电脑上裸跑 npm run develop,我的电脑不认识 postgres 这个主机名,得写 localhost。而且端口也不是默认的 5432,我映射出来的是一个新端口。
更烦的是:每次本地开发改成 localhost:新端口,要部署时又得改回 postgres:5432。这个 .env 文件来回改,一不小心把开发密码提交到 Git 就炸了。
我跟 AI 说:太蠢了,有没有办法让本地配置和生产配置彻底分开?
它终于告诉我 Strapi 有个官方机制——环境特定配置。在 config/env/development/ 下放一个 database.ts,Strapi 检测到 NODE_ENV=development 时会自动加载它,覆盖默认配置:
config/
├── database.ts ← 生产用,读环境变量
└── env/
└── development/
└── database.ts ← 本地开发用,硬编码 localhost:35432两套配置物理隔绝。本地跑 develop 永远连本地库,生产构建走默认配置读 Docker 注入的环境变量。再也不用来回改 .env 了。
我学到的一件事:AI 给的方案,往往是"最直接但不一定最优"的。你得追问"有没有框架官方推荐的做法",或者要求他上网搜索,它才会翻出真正好用的机制。
部署:Strapi 的开发态和生产态是两个东西
最后一个坑。把 Strapi 打成 Docker 镜像时(docker的内容之后有单独文章再说),AI 给了一个标准的 Dockerfile——装依赖、构建、启动。
跑不起来。报 Cannot find module 各种缺包。
问题出在 Strapi 的 develop 和 start 模式完全不同:
develop:动态编译 Admin 后台面板,支持热重载,需要 devDependenciesstart:启动预编译好的生产包,只需要 production 依赖
AI 给的 Dockerfile 只装了 production 依赖然后跑 start——生产环境没问题。但我在开发服务器上想用 develop 模式实时改东西,缺了 devDependencies 直接起不来。
解决方案是打两个镜像:
- 生产镜像
myblog-backend:latest:多阶段构建,先装全量依赖编译 Admin 面板,再拷贝编译产物到只有 production 依赖的精简运行层。跑npm run start。 - 开发镜像
myblog-backend:latest-dev:装全量依赖,挂载代码目录,跑npm run develop,支持热重载。
一个 release-backend.sh 脚本,传入 NODE_ENV 决定打哪个镜像。
最后
那句话我想再说一遍:前期多想五分钟,后期少改五小时。
模型先建到这。它后来又如何进化呢,下一篇接着聊。